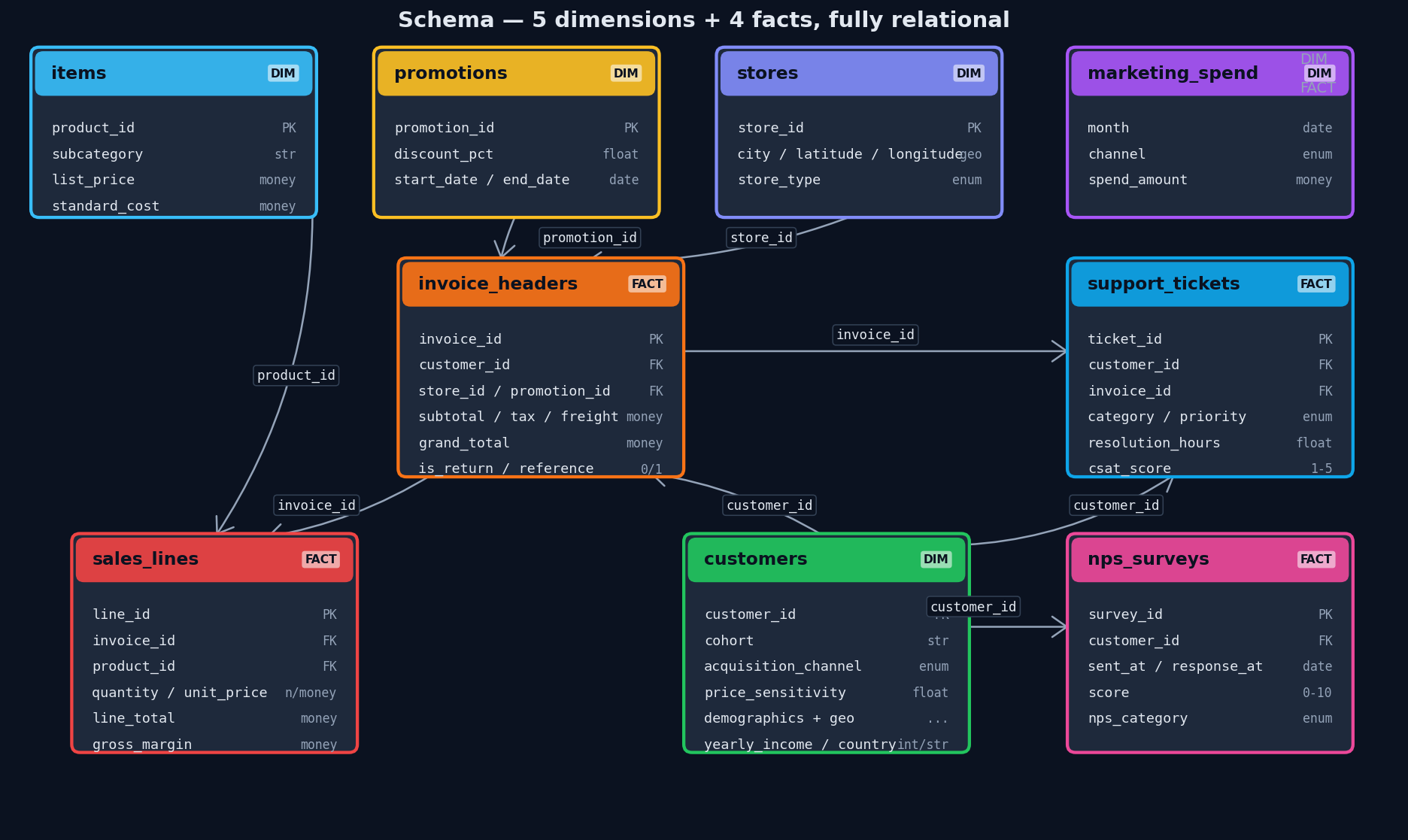
Schema — 5 dimensions + 4 facts, fully relational
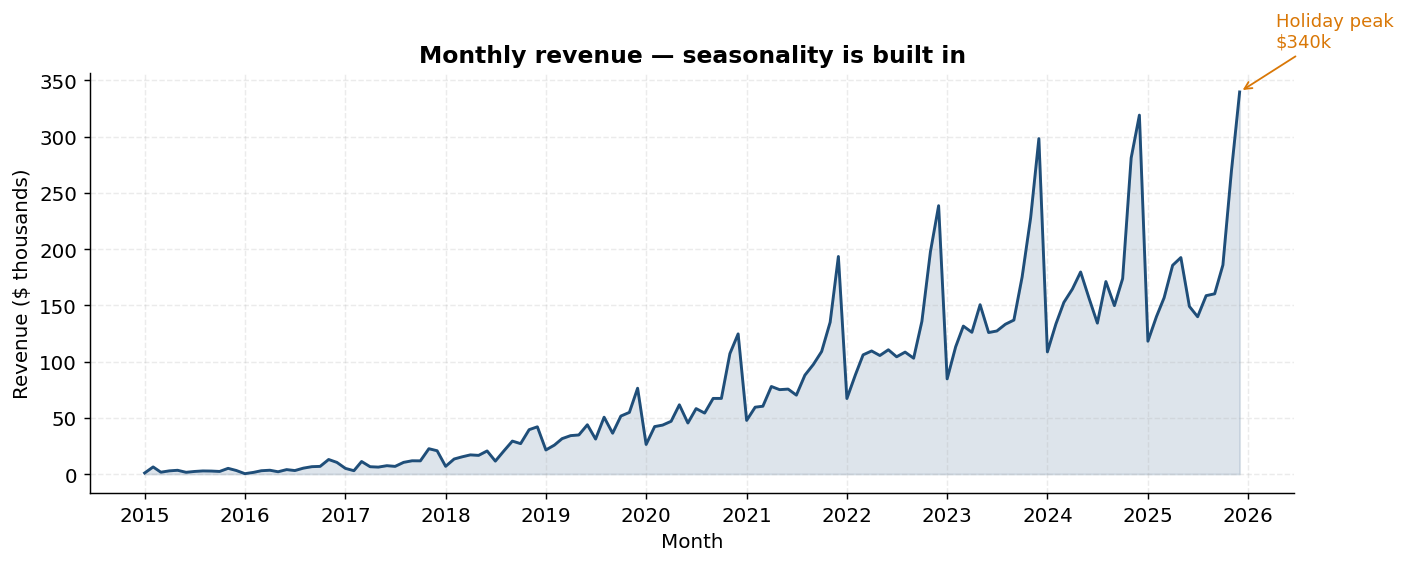
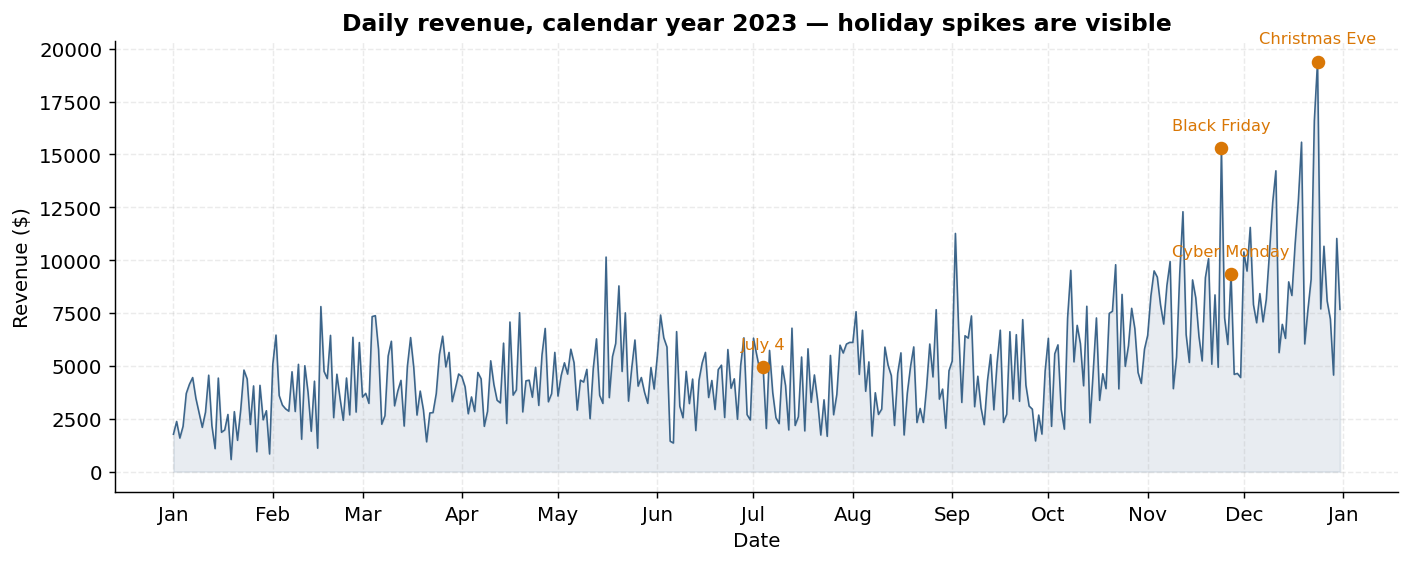
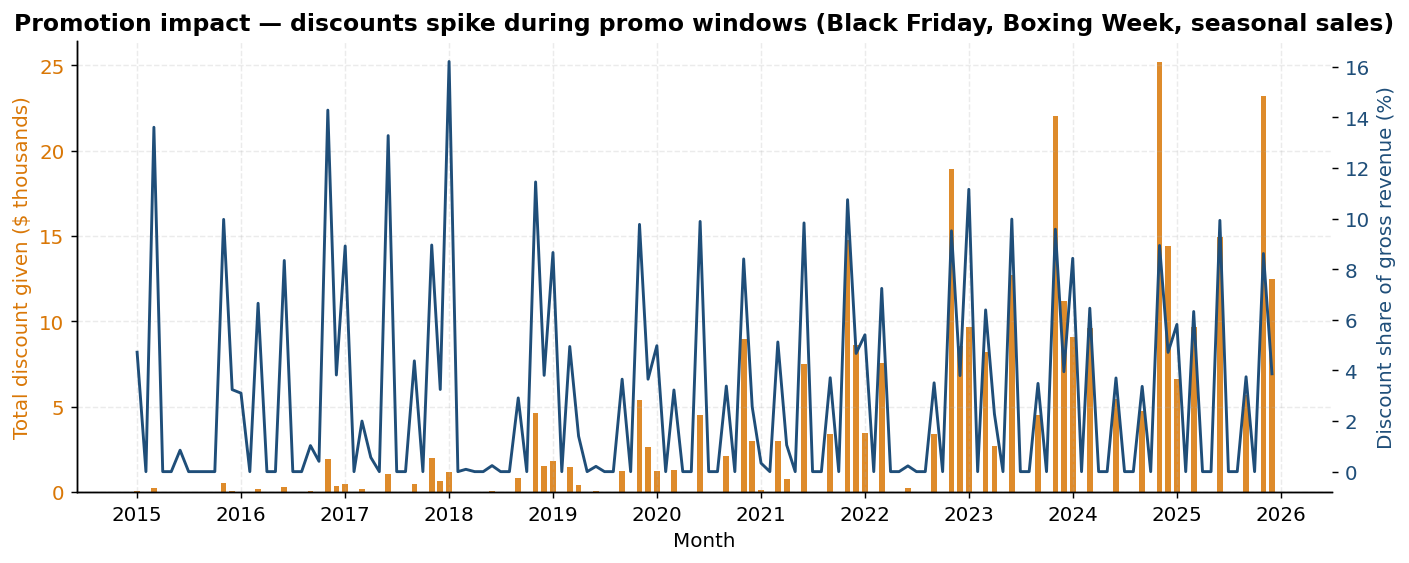
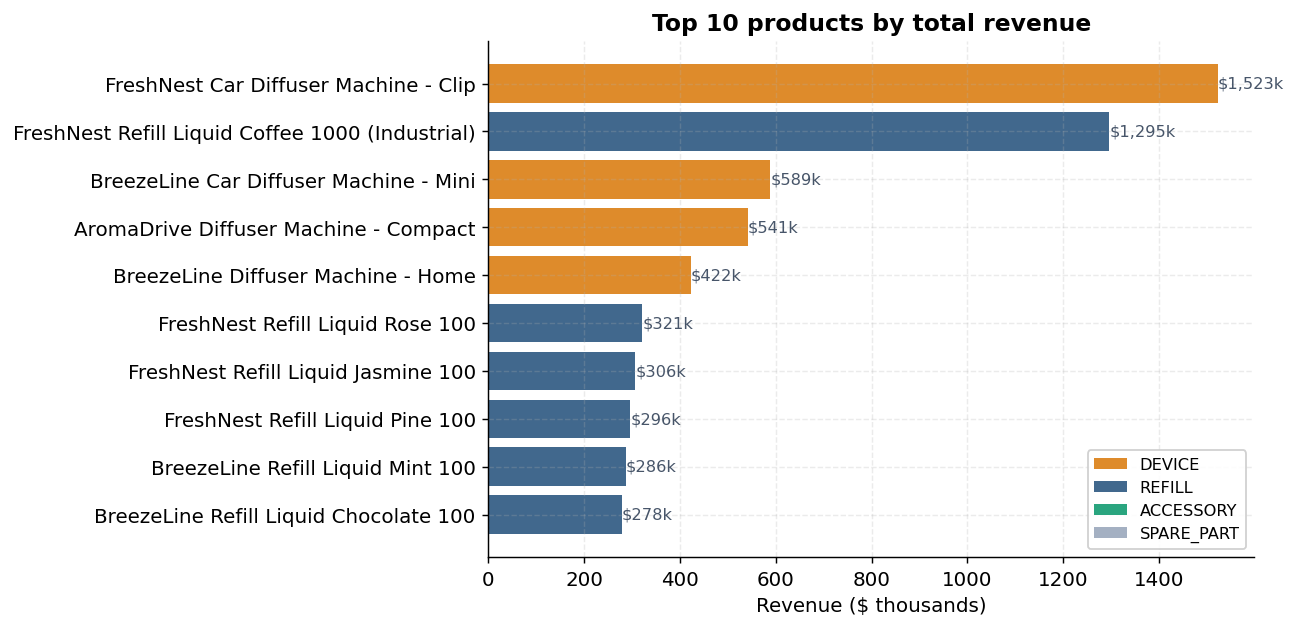
Header / line invoice split mirrors AdventureWorks' SalesOrderHeader / SalesOrderDetail, with three dates per invoice (order, ship, due), full money decomposition (subtotal → discount → tax → freight → grand_total), and explicit gross-margin tracking on every line. Plus voice-of-customer extensions: marketing spend, support tickets, NPS surveys.
| File | Type | Sample rows | Key fields |
|---|---|---|---|
items.csv | dim | 98 | product_id, list_price, standard_cost, subcategory |
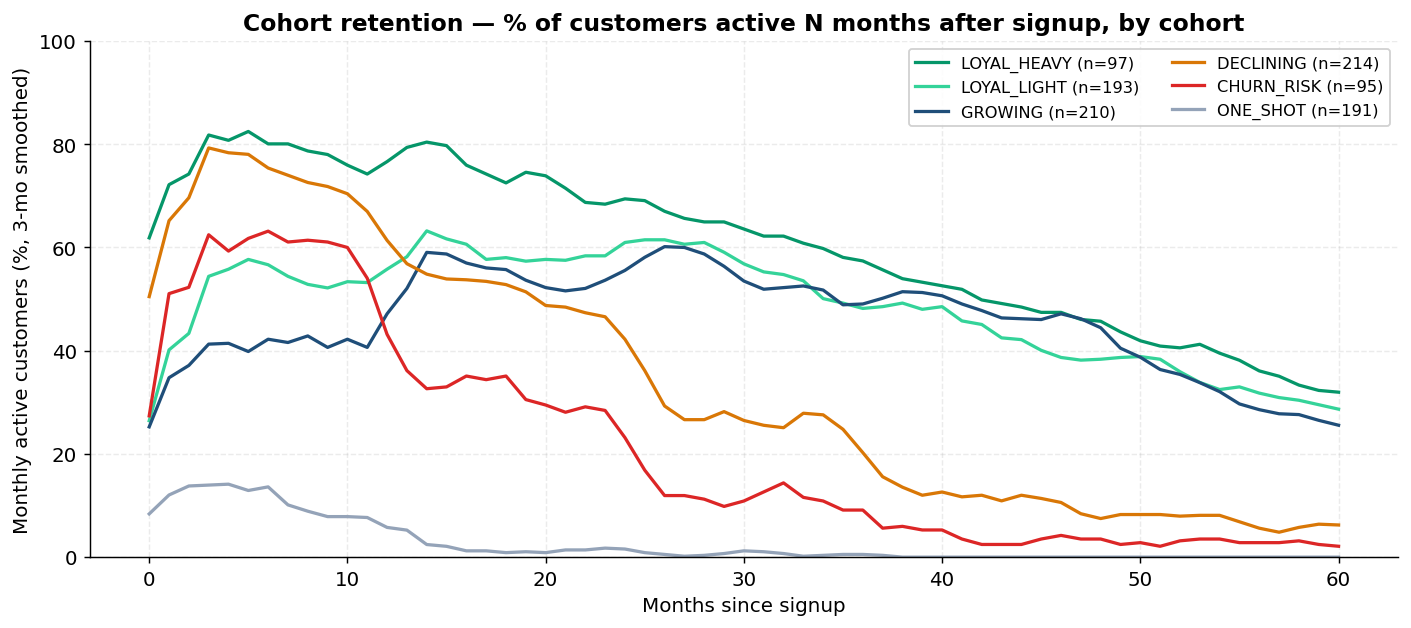
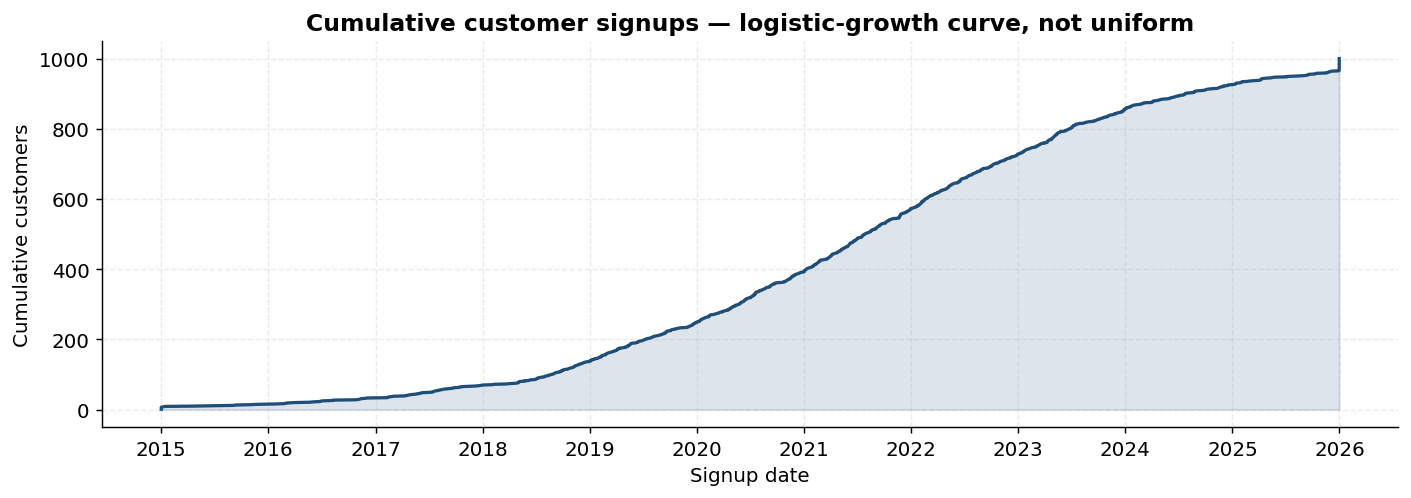
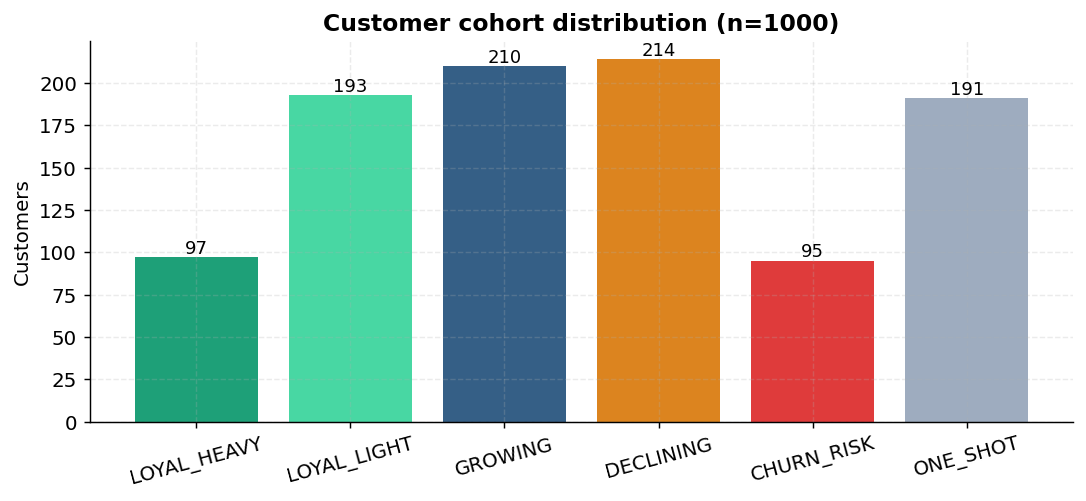
customers.csv | dim | 1,000 | customer_id, demographics, geography, cohort, price_sensitivity, acquisition_channel |
stores.csv | dim | 8 | store_id, latitude, longitude, store_type |
promotions.csv | dim | 66 | promotion_id, discount_pct, category_scope |
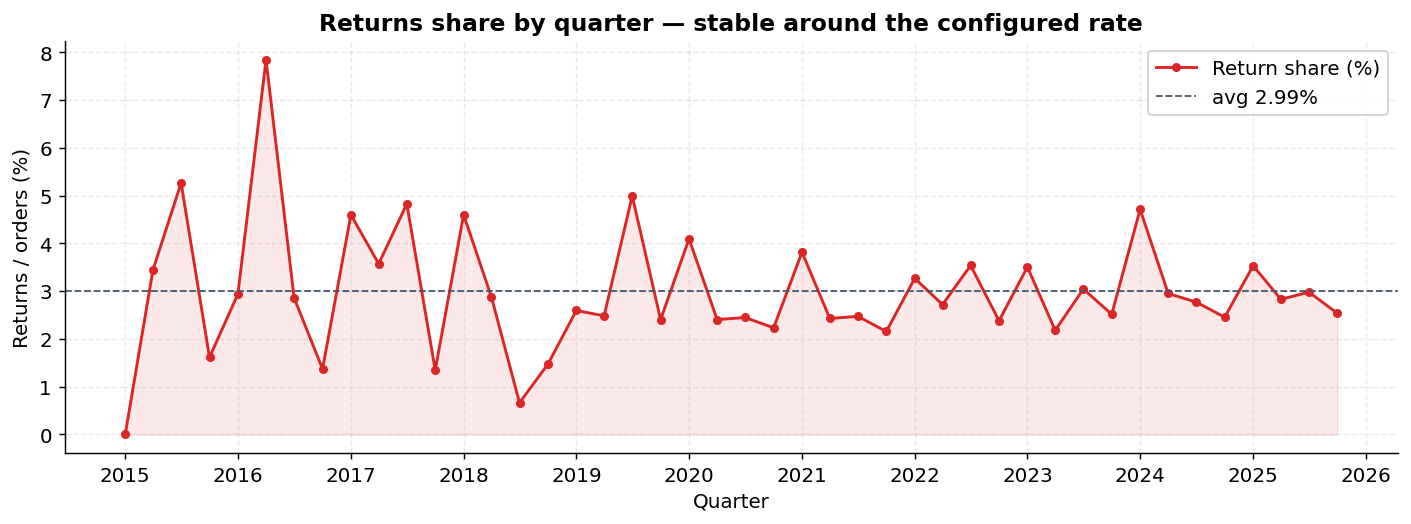
invoice_headers.csv | fact | 54,100 | 3 dates, full money decomp, payment_method, is_return |
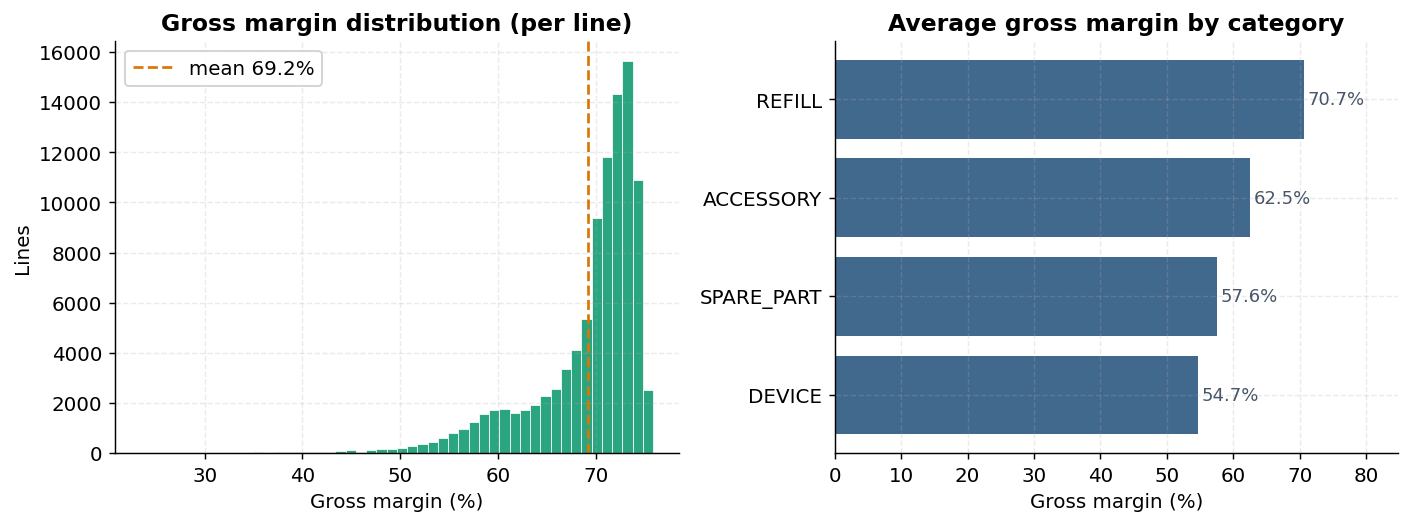
sales_lines.csv | fact | 100,627 | quantity, unit_price, discount_pct, line_total, gross_margin |
marketing_spend.csv | fact | 792 | per-month-per-channel spend with holiday boost |
support_tickets.csv | fact | 284 | category, priority, resolution time, csat_score |
nps_surveys.csv | fact | 2,765 | quarterly survey, ~55% response, score 0–10 |