Six product decisions that turn synthetic data from "dummy CSVs" into a production-grade dataset you can train models on, ship demos with, or teach from.
⚡
Massive volume, instantly
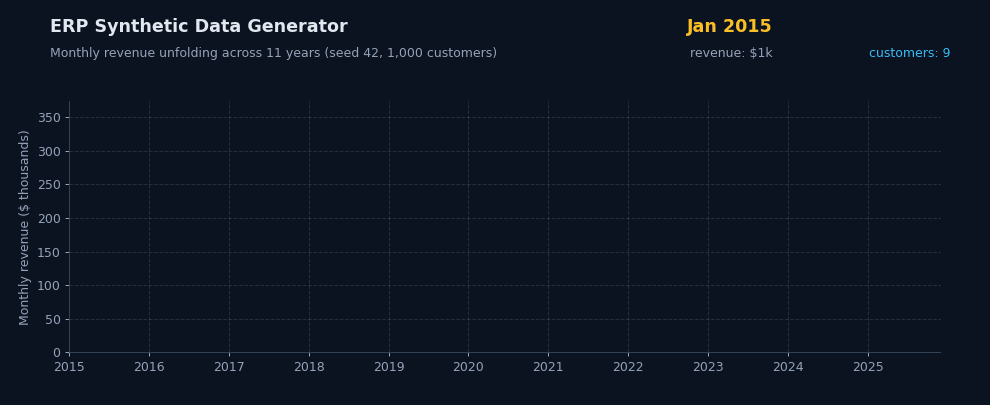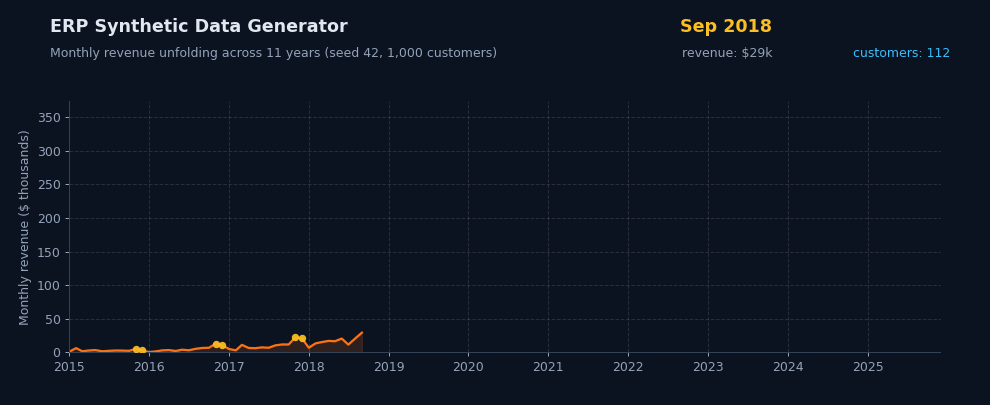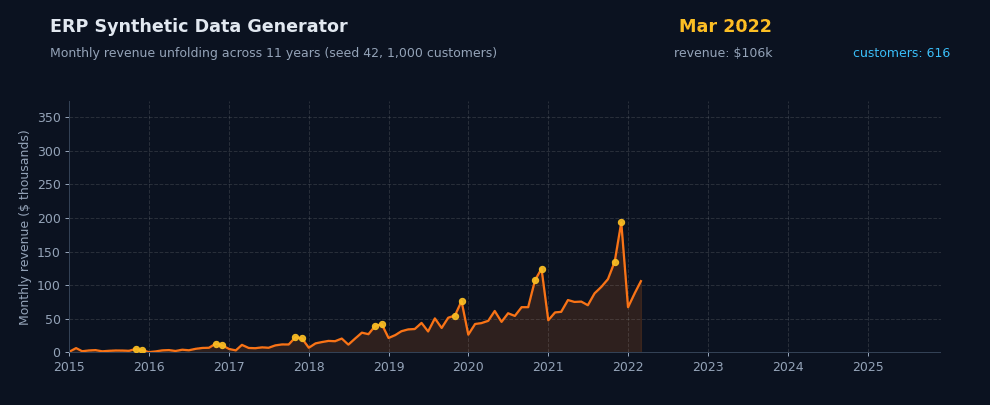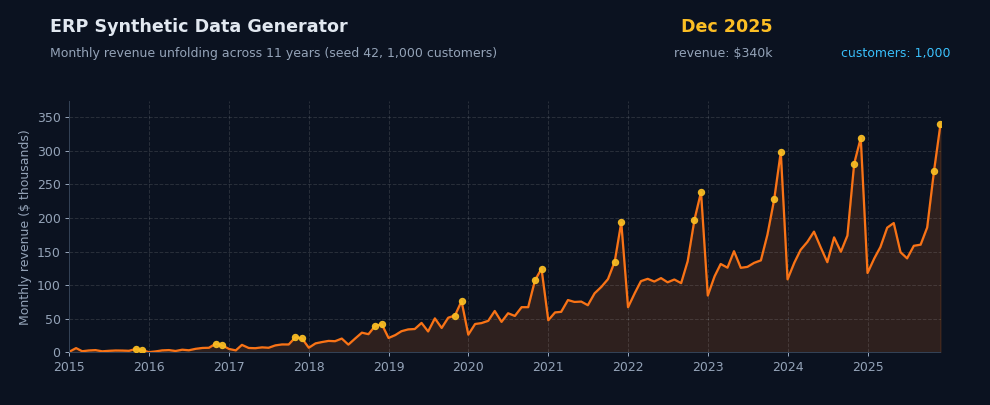
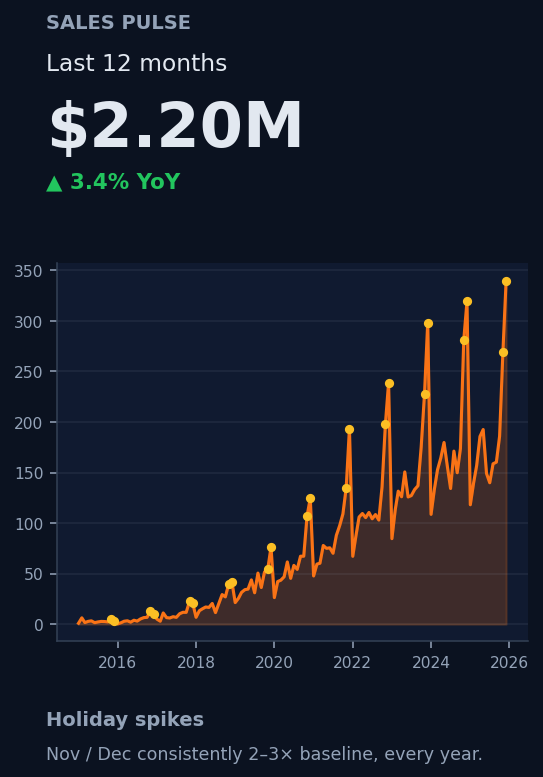
Generate hundreds of thousands of sales lines across nine relational tables in seconds. Streaming output keeps memory flat — push to millions of rows on a laptop without breaking a sweat.
★
Scientifically grounded
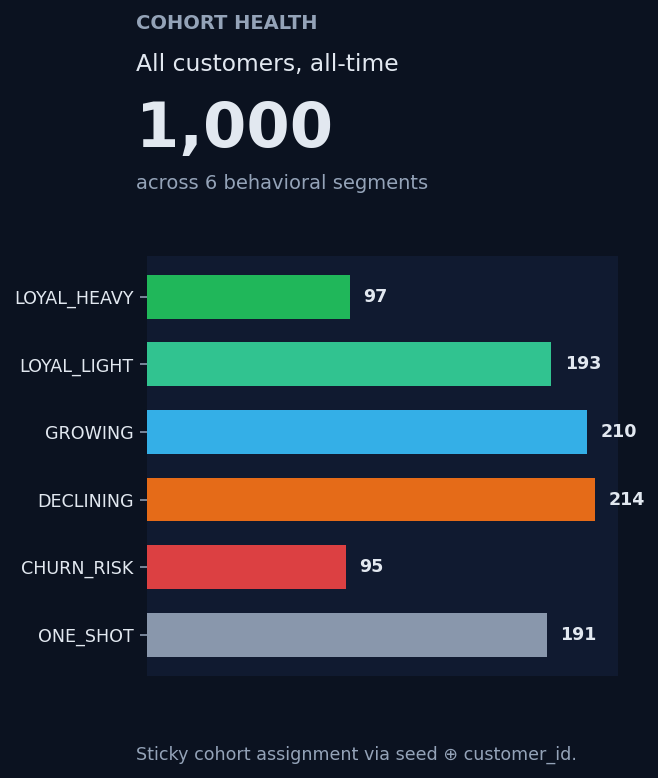
Cohort behavior anchored in buy-till-you-die customer-base models from the marketing-science literature. Discrete choice from McFadden's Nobel-winning framework. Schema follows Microsoft AdventureWorks. Ten cited papers.
⚙
Highly customizable
Twenty-plus controls over market, seasonality, inflation rate, returns probability, promotion frequency, customer field completeness, basket composition. Every realism axis has a knob.
↗
Unlimited data export
Plain CSV. Works with pandas, Excel, Power BI, Tableau, dbt, DuckDB, Postgres, Snowflake — anything that reads a delimited file. No vendor lock-in. No row caps. No throttling.
🌍
Multi-market by design
US, GCC, and EU presets out of the box. Locale, currency, VAT, weekend (Sat/Sun vs Fri/Sat), payment methods, plus market-specific holiday calendars (Black Friday, Christmas, Ramadan, Eid, Boxing Week) — all swappable.
⟲
Reproducible to the byte
One seed value drives every random number in the system. Run twice → identical CSVs, byte-for-byte. Continuous integration verifies this on every push. Your demos won't drift.